Зміст
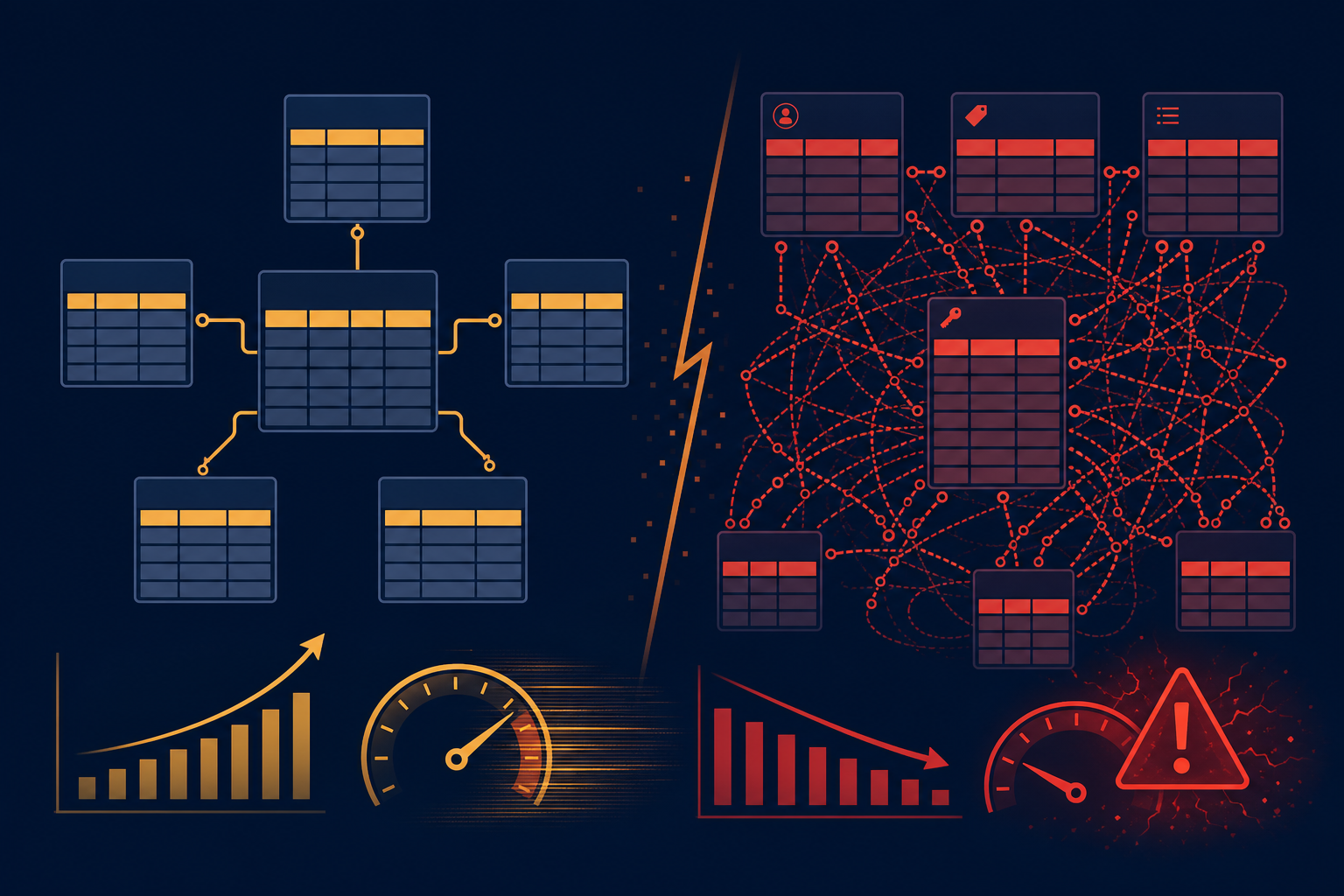
Розробники ERP знову й знову приходять до однієї й тієї ж ідеї: замість десятків таблиць із колонками — три універсальні сутності, і будь-яке поле додається без міграції. Патерн EAV (Entity–Attribute–Value) — «сутність, атрибут, значення» — на демо виглядає майже ідеально. Картку клієнта збирають за хвилину. Новий довідник — один рядок у метаданих. Архітектор отримує схвалення, команда радіє відсутності ALTER TABLE.
Через два–три роки та сама архітектура перетворюється на вузьке місце: картки відкриваються секундами, звіти рахуються годинами, адміністратори БД живуть у планах виконання запитів, а розробники бояться чіпати «універсальний рушій». Проблема не в тому, що EAV «поганий». Проблема в тому, що він вирішує задачу гнучкості ціною продуктивності, складності розробки й зростання вартості супроводу — і ця ціна стає видимою лише коли даних уже багато.
Ця стаття — поглиблений розбір EAV в контексті ERP. Якщо вас цікавить ширший погляд на універсальність як архітектурну помилку, див. найдорожчу помилку в архітектурі ERP. Тут фокус на механіці: чому патерн притягує, як він ламає БД і що використовувати замість нього.
Ключові висновки
EAV — пастка відкладеної складності. На старті виграєте в швидкості змін схеми; на горизонті мільйонів рядків програєте в кожному SELECT.
Кожне поле — додатковий JOIN. Десять атрибутів — десять з’єднань; п’ятдесят — запит, який оптимізатор не стабілізує.
Індекси й типізація ламаються в одній колонці value. Пошук за телефоном і фільтр за ціною вимагають різних стратегій; універсального індексу не існує.
Звіти й аналітика — слабке місце EAV. Засоби бізнес-аналітики й регламентована звітність очікують таблиці з колонками, а не розгортання атрибутів.
EAV доречний на периферії, не в ядрі. Налаштування, рідкісні користувацькі поля, прототипи — так. Замовлення, залишки, проводки — ні.
EAV надто хороший на етапі проєктування. Саме тому досвідчені архітектори не будують на ньому ядро ERP.
Вступ: чому EAV повертається знову й знову
ERP живе у світі, де вимоги змінюються швидше за релізний цикл. Сьогодні потрібен артикул, завтра — серійний номер, післязавтра — температура зберігання й ще п’ятдесят полів «лише для цього клієнта». Класична реляційна модель відповідає міграціями: ALTER TABLE, деплой, регресія. EAV обіцяє ніколи не чіпати схему — лише додавати рядки в таблицю значень.
Для архітектора, який бачив, як інтегратори місяцями погоджували додавання колонки в продакшені, це звучить як порятунок. Для бізнесу на презентації — як «система налаштовується без програмістів». Для розробника на першому спринті — як елегантна абстракція. Саме тому EAV відроджується в кожному поколінні ERP-проєктів, попри гори звітів про провали попередніх команд.
EAV простими словами: замість того, щоб зберігати клієнта в рядку таблиці customers з колонками name, phone, email, ви зберігаєте ідентифікатор сутності і набір пар «ім’я атрибута → значення» в окремих рядках. Одна таблиця описує все. Гнучкість нескінченна — до першого важкого звіту.
Розділ 1. Що таке EAV
Класична реляційна модель
Таблиця клієнтів — зразок, який усі розуміють:
| id | name | phone | |
|---|---|---|---|
| 1 | Іван Петров | +380501234567 | [email protected] |
Переваги:
- Прості запити —
SELECT name, phone FROM customers WHERE id = 1. - Індекси працюють передбачувано —
INDEX(phone)прискорює пошук за телефоном. - Зрозуміла структура — схема видна в
\d customers, в IDE, в документації.
СУБД оптимізована під таку модель десятиліттями. Тип стовпця відомий, статистика осмислена, план виконання стабільний.
Модель EAV
Замість колонок — рядки значень:
| entity_id | attribute | value |
|---|---|---|
| 1 | name | Іван Петров |
| 1 | phone | +380501234567 |
| 1 | [email protected] |
У реальних системах схема трохи складніша: окремі таблиці entities, attributes, attribute_values з типами й посиланнями. Але ідея та сама: структура даних описується даними, а не DDL.
Чому розробники вважають це геніальним:
- Можна додавати поля без зміни схеми БД — новий рядок у
attributes, неALTER TABLE. - Можна створювати будь-які сутності —
entity_type = 'product','order','warehouse_cell'. - Не потрібні міграції на кожне поле клієнта (теоретично).
- Можна будувати універсальний конструктор об’єктів — інтерфейс читає метадані й малює форму.
На папері проблему «бізнес просить ще одне поле» вирішено назавжди.
Розділ 2. Чому EAV виглядає ідеальним рішенням для ERP
Вимоги бізнесу постійно змінюються
Типова еволюція картки товару:
| Коли | Що просять |
|---|---|
| Сьогодні | Артикул, виробник |
| Завтра | Серійний номер, колір |
| Через місяць | Термін придатності, температура зберігання |
| Через рік | Ще 50 полів під галузь, філію, регулятора |
У нормалізованій моделі кожен крок — міграція, тести, погодження з адміністратором БД, оновлення звітів. В EAV — конфігурація: адміністратор або інтегратор додає атрибут в інтерфейсі. Для власника продукту це конкурентна перевага: швидше реагувати на ринок.
Ілюзія нескінченної гнучкості
Архітектор думає:
«Ми створимо одну універсальну таблицю й більше ніколи не змінюватимемо структуру бази.»
Звучить красиво. Звучить як кінець війни між розробкою й впровадженням. Звучить як масштабований продукт для тисячі клієнтів із різними робочими процесами.
Мрія про повністю універсальну ERP
На слайді:
- будь-який довідник;
- будь-який документ;
- будь-який бізнес-процес;
- будь-який набір полів —
усе зберігається однаково. Один рушій збереження, один рушій звітів, один API getField('...'). Здається, що архітектурну проблему ERP вирішено назавжди.
На практиці ви не вирішили проблему — ви відклали її в шар запитів, індексів і налагодження. Докладніше про ціну універсальності — у статті про універсальну архітектуру ERP.
Розділ 3. Перший удар по продуктивності
Простий SELECT перетворюється на кошмар
У звичайній моделі:
SELECT name, phone, email
FROM customers
WHERE id = 1;
Один пошук за первинним ключем. Мікросекунди.
В EAV для тих самих трьох полів:
SELECT
MAX(CASE WHEN a.code = 'name' THEN av.value_string END) AS name,
MAX(CASE WHEN a.code = 'phone' THEN av.value_string END) AS phone,
MAX(CASE WHEN a.code = 'email' THEN av.value_string END) AS email
FROM entities e
JOIN attribute_values av ON av.entity_id = e.id
JOIN attributes a ON a.id = av.attribute_id
WHERE e.id = 1
AND e.entity_type = 'customer'
GROUP BY e.id;
Уже три атрибути — JOIN, GROUP BY, умовний агрегат (розгортання). Альтернатива — окремий JOIN на кожне поле:
SELECT v_name.value AS name,
v_phone.value AS phone,
v_email.value AS email
FROM entities e
JOIN attribute_values v_name ON v_name.entity_id = e.id
JOIN attributes a_name ON a_name.id = v_name.attribute_id AND a_name.code = 'name'
JOIN attribute_values v_phone ON v_phone.entity_id = e.id
JOIN attributes a_phone ON a_phone.id = v_phone.attribute_id AND a_phone.code = 'phone'
JOIN attribute_values v_email ON v_email.entity_id = e.id
JOIN attributes a_email ON a_email.id = v_email.attribute_id AND a_email.code = 'email'
WHERE e.id = 1;
Для кожного поля — додаткове з’єднання. Картка клієнта з 20 полями — 20 JOIN лише щоб показати форму.
Зростання кількості з’єднань
| Полів на об’єкті | Характер запиту |
|---|---|
| 10 | Терпимо на малих обсягах |
| 50 | Помітне навантаження на CPU, складні плани |
| 200 | Окремий інженерний проєкт, кеші, денормалізація |
Вартість читання зростає лінійно з числом атрибутів у найгіршому випадку і гірше при фільтрації за кількома полями одночасно.
Оптимізатор БД починає страждати
Симптоми:
- Складні плани виконання — десятки вузлів, nested loop, hash join на мільйонах рядків у
attribute_values. - Нестабільні запити — після
ANALYZEплан змінюється, учора швидкий звіт сьогодні «висить». - Несподівані деградації — додали один атрибут, і запит списку замовлень сповільнився в п’ять разів, бо оптимізатор обрав інший порядок JOIN.
Реляційні СУБД чудово оптимізують фіксовані схеми. EAV перетворює кожен SELECT на динамічну головоломку.
Розділ 4. Індекси перестають рятувати
У звичайній таблиці індекс очевидний
CREATE INDEX idx_customers_phone ON customers(phone);
SELECT * FROM customers WHERE phone = '+380501234567';
Index scan, тисячі рядків на секунду. Адміністратор БД щасливий.
В EAV усе зберігається в універсальних стовпцях
Логічно:
attribute = 'phone'
value = '+380501234567'
Фізично — мільйони рядків у attribute_values, де в value_string лежать імена, телефони, дати, JSON і числа впереміш.
Проблеми:
- Індекс лише за
valueмарний для селективності — половина таблиці «Іван» і «червоний». - Індекс за
(attribute_id, value_string)допомагає одному атрибуту, але роздувається з кожним новим типом сутності. - Композитні індекси множаться: для phone, для sku, для status — окремі стратегії, бо типи й кардинальність різні.
Індексів стає надто багато
Для кожної «гарячої» групи атрибутів адміністратор БД додає частковий або складений індекс. Підсумок:
- зростання розміру БД — індекси зрівняні з даними;
- зростання споживання RAM — hot set не вміщується в пам’ять;
- сповільнення запису — кожна вставка значення оновлює кілька B-tree.
У нормалізованій таблиці один запис замовлення — один рядок, кілька індексів. В EAV один запис замовлення з 30 полями — 30 INSERT і каскад оновлень індексів.
Розділ 5. Фільтрація стає дорогою
Бізнес хоче простий звіт
«Покажи товари червоного кольору дорожче 100 євро.»
У нормальній схемі:
SELECT id, name, price
FROM products
WHERE color = 'red'
AND price > 100;
Дві умови на типізованих стовпцях. Індекс за (color, price) або bitmap plan — стандартна задача.
В EAV — ланцюжок JOIN
Потрібно знайти сутності, у яких одночасно:
- є атрибут
colorзі значенням'red'; - є атрибут
priceзі значенням> 100.
Типовий патерн:
SELECT e.id
FROM entities e
WHERE e.entity_type = 'product'
AND e.id IN (
SELECT av1.entity_id
FROM attribute_values av1
JOIN attributes a1 ON a1.id = av1.attribute_id
WHERE a1.code = 'color' AND av1.value_string = 'red'
)
AND e.id IN (
SELECT av2.entity_id
FROM attribute_values av2
JOIN attributes a2 ON a2.id = av2.attribute_id
WHERE a2.code = 'price' AND av2.value_number > 100
);
Два підзапити, чотири JOIN, перетин множин. Додайте сортування за назвою, групування за категорією й ліміт на сторінці — запит роздувається далі.
Складні фільтри — катастрофа
Особливо болісно, коли в одному звіті:
- десятки атрибутів у SELECT;
- фільтри за п’ятьма–десятьма полями;
- GROUP BY і агрегації;
- сортування за нетипізованим
value.
Кожна умова — ще одна гілка в плані. Користувач чекає. Бізнес питає, чому «простий список» не працює.
Розділ 6. Звіти стають найслабшим місцем
ERP живе звітами
Операційний облік — форми й картки. Але цінність ERP для керівництва — у зведеннях: продажі за регіонами, залишки на дату, дебіторка, собівартість, план-факт. Ці запити:
- торкаються великих обсягів даних;
- виконуються регулярно й паралельно;
- не терплять деградації «у п’ять разів повільніше з понеділка».
EAV погано підходить для аналітики
Причини:
- багато JOIN — кожен стовпець звіту розгортається з атрибутів;
- багато перетворень —
CAST,CASE, приведення типів ізvalue_string; - складна агрегація —
SUM(price)вимагає спочатку зібрати price в рядок на кожну сутність.
Частий наслідок: звіти переїжджають у нічний ETL в окреме сховище з нормалізованими вітринами. Ядро ERP на EAV залишається для введення; аналітика живе в копії даних. Ви платите за дві моделі замість однієї.
Чому засоби бізнес-аналітики не люблять EAV
Power BI, Metabase, внутрішні конструктори очікують:
- таблиці з іменами;
- колонки з типами;
- зв’язки за зовнішніми ключами.
EAV змушує або писати представлення з сотнями рядків, або налаштовувати семантичний шар, який емулює нормальну схему поверх EAV. По суті ви будуєте нормалізовану модель вдруге — поверх першої, щоб виправити архітектурний вибір.
Розділ 7. Типізація починає руйнуватися
В одній колонці зберігається все
Типова універсальна комірка value_string (або кілька колонок value_*):
100
150.5
Іван Петров
2025-01-01
true
{"nested": "json"}
Що таке значення?
Для СУБД і оптимізатора — рядок. Для бізнесу — число, дата, прапорець, посилання. Застосунок має вгадувати тип за метаданими атрибута при кожній операції.
Кожна операція вимагає перетворення
WHERE CAST(av.value_string AS NUMERIC) > 100
- CAST вбиває використання індексу за значенням.
- Помилки типів спливають під час виконання:
'N/A'у полі ціни ламає звіт. - Порівняння дат як рядків дає хибне сортування без суворого формату.
Постійні CAST, CONVERT, перевірки в застосунку — додатковий CPU на кожному рядку й джерело тихих багів у звітності.
Розділ 8. Обсяг даних зростає вибухово
Проста математика
| Об’єктів | Полів на об’єкт | Рядків у attribute_values |
|---|---|---|
| 100 000 | 100 | 10 000 000 |
| 1 000 000 | 50 | 50 000 000 |
| 500 000 замовлень | 80 полів | 40 000 000 лише за замовленнями |
У нормалізованій моделі 100 000 клієнтів — 100 000 рядків. В EAV — 100 000 × N атрибутів.
Що відбувається далі
Зростають:
- таблиці — резервне копіювання й відновлення вимірюються годинами;
- індекси — перебудова й vacuum стають плановим проєктом;
- реплікація — лаг read replica помітний операторам;
- вартість хмари — більше диска, більше IOPS, більше RAM.
Кожне нове поле збільшує обсяг
Навіть якщо атрибут заповнений у 1% записів, у горизонтальній EAV-моделі порожнє значення часто все одно зберігається або ускладнює запити LEFT JOIN. Додавання «рідкісного» поля в конфігураторі не безкоштовне для інфраструктури.
Розділ 9. Чому розробка теж стає складнішою
Запити важко читати
Простий список замовлень за тиждень в EAV — сторінка SQL із підзапитами, псевдонімами av_status, a_status, av_total. Перегляд коду перетворюється на археологію. Новий розробник не може відповісти на питання «які поля у замовлення?» без запиту до attributes.
Помилки стають дорожчими
- Логіка розподілена між метаданими, універсальним сервісом і SQL.
- Дані неочевидні — друкарська помилка в
codeатрибута ламає звіт для одного клієнта. - Важко налагоджувати — баг «не той статус» вимагає пройти ланцюжок entity → values → override клієнта 17.
Залежність від «магів»
З’являються два–три людини, які «розуміють рушій». Вони йдуть — онбординг займає місяці. Це не зріла архітектура, а критична залежність від кількох ключових людей. Див. також чому ERP перетворюються на монолітів — EAV прискорює той самий процес.
Розділ 10. Реальна історія більшості ERP на EAV
Типова траєкторія — не теорія, а патерн із десятків проєктів.
Етап 1. Захват
«Ми створили універсальну платформу. Будь-який довідник за день. Конкуренти роблять міграції — ми робимо конфіг.»
Етап 2. Зростання
З’являються клієнти, документи, мільйони рядків у attribute_values. Функціональність зростає. Усе ще терпимо на потужному залізі.
Етап 3. Сповільнення
Скарги користувачів:
- довго відкриваються картки;
- повільно працюють звіти;
- гальмує пошук у довідниках.
Підтримка посилається на «великий обсяг даних». Адміністратори БД вперше відкривають EXPLAIN ANALYZE.
Етап 4. Костилі
- кеші карток і списків у Redis;
- матеріалізовані представлення для топ-10 звітів;
- денормалізовані таблиці
orders_flatдля інтерфейсу; - окремий пошуковий індекс (Elasticsearch, OpenSearch) для довідників.
Кожен костиль — визнання, що EAV не тягне критичний контур обробки.
Етап 5. Фактична відмова від EAV
Система обростає спеціалізованими таблицями: orders, order_lines, inventory_movements. EAV залишається для «кастомних полів» і застарілих конфігурацій. Виходить гібрид — найчесніша архітектура, але дорога: ви платите за обидва світи, поки не виріжете старе ядро.
Розділ 11. Коли EAV справді корисний
EAV — не антипатерн скрізь. Це інструмент із вузькою зоною застосування.
Налаштування системи
Конфігурація модулів, прапорці функцій, параметри інтеграцій — мало записів, рідкісні зміни, немає важкої аналітики.
Метадані
Коли структура заздалегідь невідома і обсяг малий: опис полів форми, схема імпорту, мапінг зовнішньої системи.
Рідко вживані додаткові поля
Користувацькі поля в картці клієнта — коментар менеджера, внутрішній код, нестандартний атрибут для однієї філії. Помилка тут не ламає баланс.
Невеликий обсяг і некритична продуктивність
Прототип, внутрішній інструмент, платформа з мінімумом коду — користувач свідомо міняє гнучкість на швидкість запитів.
Правило великого пальця: якщо від поля залежать залишки, гроші, податки або регламентований звіт — це колонка в типізованій таблиці, не рядок в EAV.
Розділ 12. Що використовувати замість EAV
Класичні нормалізовані таблиці
Основа більшості успішних ERP. Замовлення — таблиця orders, рядки — order_lines, зовнішні ключі, інваріанти в коді або CHECK. Нудно, передбачувано, швидко.
JSON-поля для рідкісних атрибутів
PostgreSQL JSONB, MySQL JSON — гнучкість без JOIN на кожне поле:
ALTER TABLE products ADD COLUMN extras JSONB;
-- extras->>'color', індекс GIN за потреби
Плюси: один рядок на товар, менше з’єднань, простіша картка. Мінуси: слабша типізація, індексація за JSON вимагає дисципліни. Підходить для периферійних даних.
Гібридна архітектура
Найпопулярніший компроміс у зрілих системах:
| Шар | Зберігання |
|---|---|
| Ядро (замовлення, товар, залишок) | Типізовані колонки |
| Розширення (кастом клієнта) | JSONB або окрема EAV-таблиця з малим обсягом |
| Налаштування інтерфейсу | Метадані |
80% запитів б’ють по нормальних таблицях; 20% терплять гнучкість.
Рушій сутностей із фізичними таблицями
Метадані описують сутність, але при публікації схеми система генерує реальні таблиці (ALTER або окремі tenant-schema). Гнучкість на етапі проєктування, продуктивність нормальної БД під час виконання. Складність — в інструменті генерації й міграціях, але це чесна складність, а не прихована в JOIN.
Висновок
Головна проблема EAV
Не в тому, що це «погана ідея». В тому, що це надто хороша ідея на етапі проєктування.
Архітектор на дошці бачить:
- гнучкість;
- універсальність;
- відсутність міграцій на кожне поле.
Він не бачить (або відкладає):
- мільйони рядків у таблиці значень;
- лавину JOIN у кожному звіті;
- руйнування індексів в одній колонці
value; - біль аналітики й бізнес-аналітики;
- зростання вартості супроводу й залежність від небагатьох «знавців».
Однаковий шлях більшості великих ERP
- Захват від універсальності.
- Боротьба з продуктивністю — кеші, залізо, адміністратори БД.
- Денормалізація — плоскі таблиці, матеріалізовані представлення.
- Повернення до спеціалізованих таблиць у ядрі.
Саме тому досвідчені архітектори використовують EAV як допоміжний інструмент — налаштування, кастомні поля, прототипи — але не будують на ньому ядро системи, через яке проходять замовлення, склад і гроші.
Якщо ви обираєте схему даних для нової ERP сьогодні, поставте одне питання: «Чи зможемо ми через три роки пояснити EXPLAIN головного звіту з продажів junior-розробнику за годину?» На нормалізованій моделі — так. На EAV у ядрі — швидше за все, ні. І це коштує дорожче за будь-яку зекономлену міграцію на старті.